The project I’m working on at the moment requires me to achieve the fastest updates I can into a moderate sized SQL Server database table. My initial attempts were adequate for the testing I was doing on my development machine but when I came to do a more thorough test in a production like environment I found that the method I was employing wasn’t even close to fast enough. At that point I seriously considered just giving up, the difference between what I had and what I needed didn’t look like an “I’ll give it a tweak” type problem it was a vast performance gulf that had to be crossed. The solution was to better understand both my application and SQL Server and here’s what I did.
The Problem
I have a table with a two part primary key and a larger than usual number of data containing columns, typically around 250. The table gets a few large selects, a very small number of inserts and a fair number of updates. The updates come in bursts and occasionally result in most or even all of the table being updated. Usually you can tip the performance balance in favour of one operation but in this case I need all of the operations to be quick! The good news is that the selects and inserts are fast enough without any specific optimisation the updates however are much too slow.
In terms of hardware and software my hands are tied and I have to use what I have. If I could throw money at this problem I’m sure it would just go away but I don’t have that luxury. For the database I’m currently running SQL Server 2012 Express on Windows Server 2012. I could probably move to SQL Server 2014 Express but there’s no budget for a pay for real version of SQL Server. What this means is that I’m limited to 1GB of memory per database instance, 4 cores on 1 processor and 10GB per database (1). The four core limit isn’t an issue as I don’t run any particularly complex queries. The 10GB database size isn’t really an issue either as my database is currently about 6GB and unlikely to grow much. The 1GB memory usage is a problem though as nearly all of the 6GB of the database could do with being in memory. The limits for SQL Server 2014 Express appear to be the same (2).
The hardware is a reasonably fast 10 core machine with 64GB ram and a four disk RAID 6 but… that’s the host and the servers are virtualized – the host is running at least half a dozen virtual machines. The total load isn’t too bad but it’s very bursty and can pummel the server for 15 minutes then die off completely for an hour.
The one thing I have going in my favour is that each table that I need to update quickly isn’t particularly large, typically around 40,000 rows with 250 columns of data (so 252 columns total). That gives a total number of data cells of 10,000,000 all of which are floats and as I don’t specify a size for the floats they will be 53 bits stored in 8 bytes giving a table size of a bit over 76MiB, lets call it 80MiB.
SQL Server Express Memory Limits
As a slight aside I read up a bit on the memory limits of SQL Server Express (I’ll only discuss 2012 and 2014 here). The feature list clearly states that each engine instance is limited to 1GB of memory but it also states that you are using Advanced Services you can access up to 4GB. I don’t really use any of the Advanced Services but my database still eats up 4GB. I’ve not found anywhere that definitively states that the engine doesn’t use some of this additional memory for optimizations, I suspect not though as that would make the Express edition too useful (3, 4). The other thing to note about memory usage in the Express edition is that it’ll free up memory if it sits idle for a while. This is a good thing for an application running on a desktop machine but not so great for a server application which will have to re-cache data after every idle period.
Getting the Fastest Updates with SQL Server 2012 Express
In order to tackle this problem properly I decided to write myself a test application that would work in a similar manner to my application. I suspected that the optimizations I’d end up with would be fairly specific to the problem I have so it was important to make the test as close to the real world environment as possible. I got a bit carried away with my performance testing and so I thought I’d share my results to justify the time I spent getting them.
The application I’m working on is Java based and uses JDBC to connect to the server so that is what my tests also do. I ran all the tests using the latest version of Java 8 and SQL Server 2012 Express. I’m using the latest version of the MS SQL JDBC libraries which at the time of writing are 4.2.6420 (version 6 libraries will probably be released soon). I have the SQL Server libraries in my own Maven repository so if you run the tests yourself you’ll probably have to tweak the POM to satisfy this dependency.
In the application updates to the data are supplied one cell at a time and so my first attempt storing this updates just wrote them away to the database as they arrived. This is the safest option as it means that as soon as a update is received it’s safely stored away. As I found in development this is easily fast enough with a small table (lets say 10,000 rows max) and a small number of tables (lets say a total database size of 250MiB) but it quickly becomes incredibly slow when the database grows. From my point of view the metric that matters is cell updates per second (c/s). I care about this metric because that’s how I receive updates from higher up in the application. If that one number is too low the performance of the whole application will drop through the floor.
Now, c/s is an interesting metric because each row actually contains 250 cells that could (realistically) be updated. In my first attempt at a solution I assumed that updates would be completely random over the table but actually in the real world that’s not the case. In the real world updates tend to cluster in rows. In other words if there’s 50 updates it’s likely that maybe only two or three rows actually got updated. This gives me an obvious avenue for optimization.
Another obvious avenue for optimization is transaction size. My first implementation created a transaction for every update but more than one query can be submitted in a single transaction so if I could bulk up each transaction perhaps I could make it go a bit faster.
In the end I came up with five update methods, there is a vaguely logical progression from one to the next but really I was making it up as I went along. Note that in the description I refer to submitting multiple queries in one transaction as batching. This is different to the batch queries in Java where each member of the batch uses the same query, the queries here are different.
Method 1 – Single Cell with Batching
In this method I submit updates that modify a single cell at a time but I can submit multiple updates in a transaction. I used this as my base line method since a batch size of 1 and single cell updating query is what got me started on this quest to find the fastest updates. This is really the worst case scenario as it assumes there’s no correlation between updates and rows of data e.g. updates are completely randomly dispersed throughout the table and updates have to be pushed to the table immediately. Every cell change creates an separate update query the only optimization possible is grouping together queries into a batch to send to the server. Additionally the code is assuming a hostile environment and is using parameterized queries to protect against injection attacks.
Method 2 – Multi-Cell with Batching
A slightly better scenario, there’s reasonable correlation between rows and updates e.g. if there are 5 updates it’s likely they all happened to the same row. The updates can be cached for a short while before being applied. This allows for the optimization of submitting just one query to update all five cells although the code assumes that the cells being updated are randomly scatted through the row. Additionally multiple queries can be submitted in a batch. The code is still assuming a hostile environment and is using parameterized queries to protect against injection attacks.
Method 3 – Multi-Cell with Batching and Constructed SQL
Essentially the same as Method 2 but this method assumes that it’s operating in a safe environment and won’t suffer SQL injection attacks and so completely constructs the SQL that is submitted to the database. The application I’m working on is web facing but this particular part of it couldn’t suffer an injection attack for several reasons so if this method is faster it seems like a reasonable approach.
Method 4 – Whole Row with Batching and Constructed SQL
After running Method 3 it occurred to me that the logical conclusion of that is to just update the whole row each time. As with Method 3 the assumption was made that this is a safe environment and therefore construction SQL is fine.
Method 5 – Sequential with Batching and Constructed SQL
After running Method 4 it occurred to me that the order the cells are presented in the query might make a difference to the query speed and so I mashed up Methods 3 and 4 to produce this method which submits the cells for update in order and can skip random cells. This method produced, in my opinion, the most interesting results.
Test Parameters
I essentially had three parameters that I could modify Cells / Query, Batch Size and Skipped Cells although the last parameter is only relevant for Method 5. The settings I used were:
- Cells / Query: 1, 10, 20, 50
- Batch Size: 1, 2, 5, 10, 25, 50, 75, 100, 150, 250, 500
- Skipped Cells: 1, 10, 20, 50, 100
The code will execute each method using a nested loop that includes batch size and cells / query. The exceptions are Method 1 where it’s fixed at a single cell per query and Method 5 which uses batch size and skipped cells. Method 1 and 2 were required to perform 1000 cell updates method 3, 4 and 5 were required to perform 10,000 cell updates. Results are presented in terms of cells updated per second (c/s). The test table is filled with random data and the updates supply random data – using all zeroes in the test table and fixed update values appeared to make the test run faster.
Full Testing Source: Wobblycogs Examples
Results
I debated sticking all the raw data directly in this page to paw over but it was too large so here are some graphs of the results.
Full results in an Excel spreadsheet: SQL Update Performance
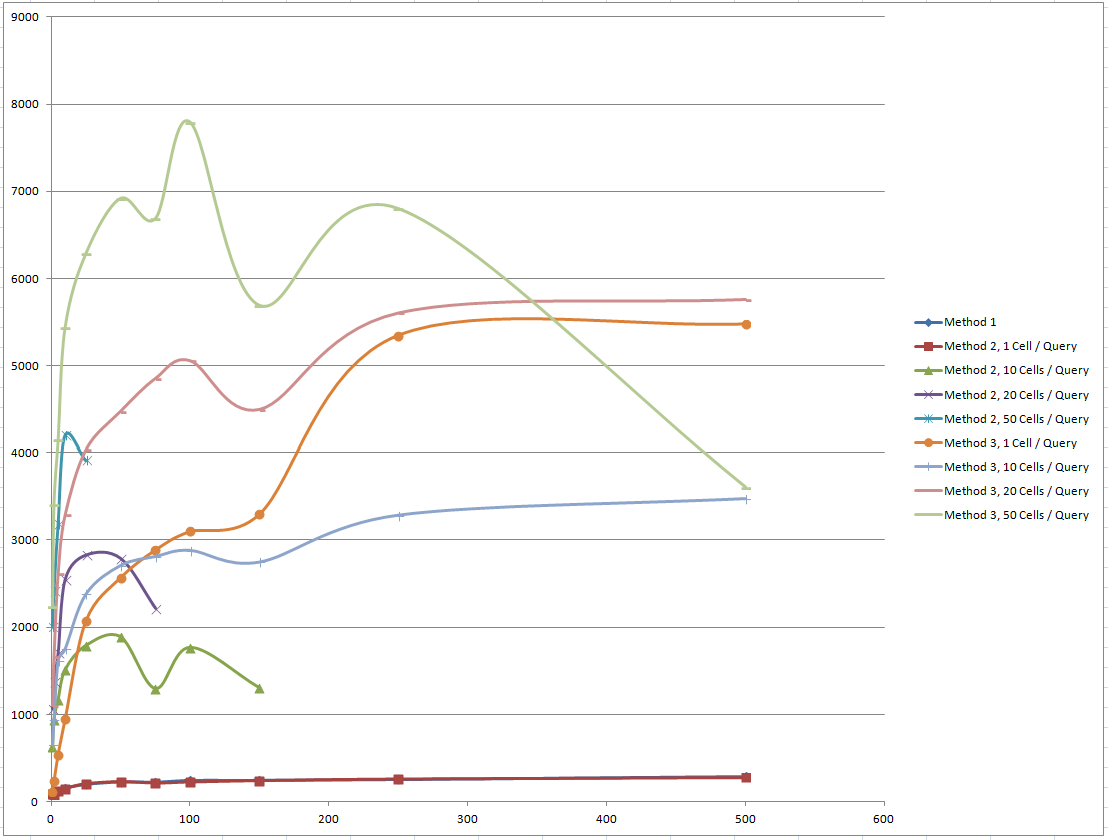
This graph shows methods 1, 2 and 3 with the various different settings they were run with (x = batch size, y = cells updated / second (c/s)). The full range of settings couldn’t be used for method 2 because of the limit of 2100 parameters per query (or batch of queries). Although the graph shows only a single run of the tests I ran the tests a few times. There’s a reasonable amount of variation in the time but the shape of the lines is quite consistent and the order of the lines is consistent. As you can see the number of c/s is massively different between the slowest method and the fastest (Method 1 is hidden under Method 1, 1 Cell / Query).
The thing that didn’t shock me was the fact that as you increase the number of cells updated in a query the c/s number increases. This wasn’t a surprise because I’d always assumed that accessing a row is going to take time but once you are there it’s probably fairly cheap to update any number of columns. What was a surprise though was how expensive it is to apply the parameters to the Method 1 and 2 queries. The Method 3 queries left the Method 2 queries for dead with Method 3 peaking at just under 8000 c/s with batches of 100 queries updating 50 cells. It’s interesting that the c/s speed drops off a cliff with the very largest batch size in Method 3. This was completely reproducible and I suspect shows an optimization within SQL Server.
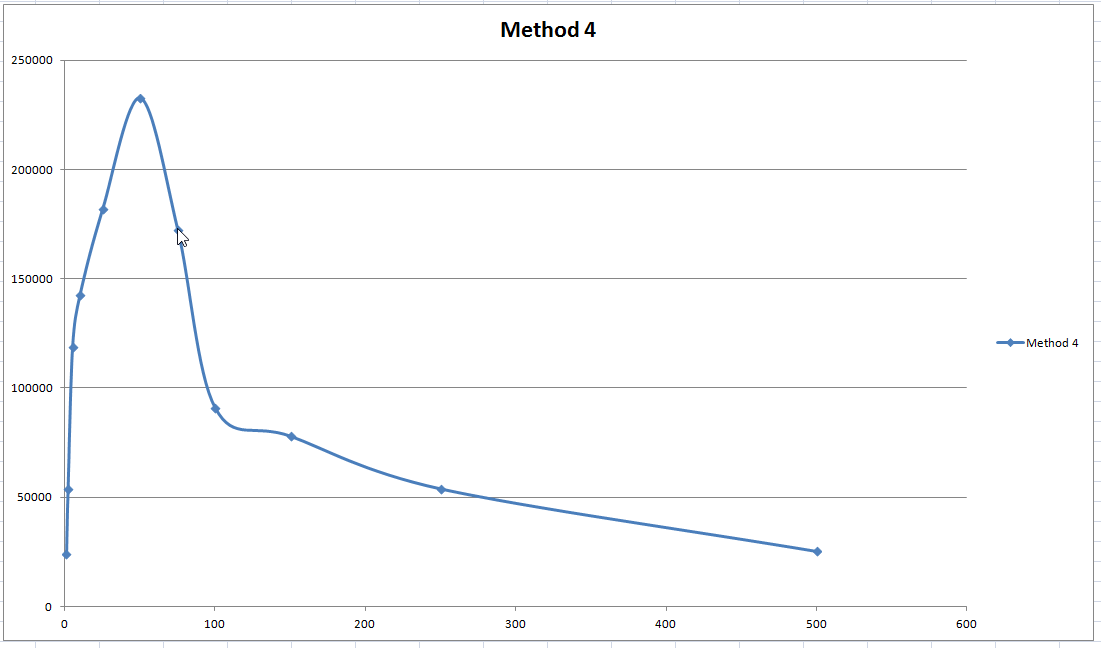
You were probably wondering why I hadn’t shown Method 4 in the chart above, well that’s because it needs it’s own scale! The performance of updating a whole row at a time was quite frankly astonishing. At it’s peak with batches of 50 queries I was seeing around 250,000 c/s. Before jumping up and shouting eureka though you’ve got to understand what this means for the application I’m working on. This speed would only be realized in the situation where updates are strongly correlated with rows. This test basically assumes that 40 rows were completely updated and the rest of the database was untouched. As it happens that assumption is not entirely false but it’s not entirely true either.
What it does mean though is that if I can cache the updates in my application and apply them in bulk I can get very good performance over the simple method of just applying updates as and when they arrive.
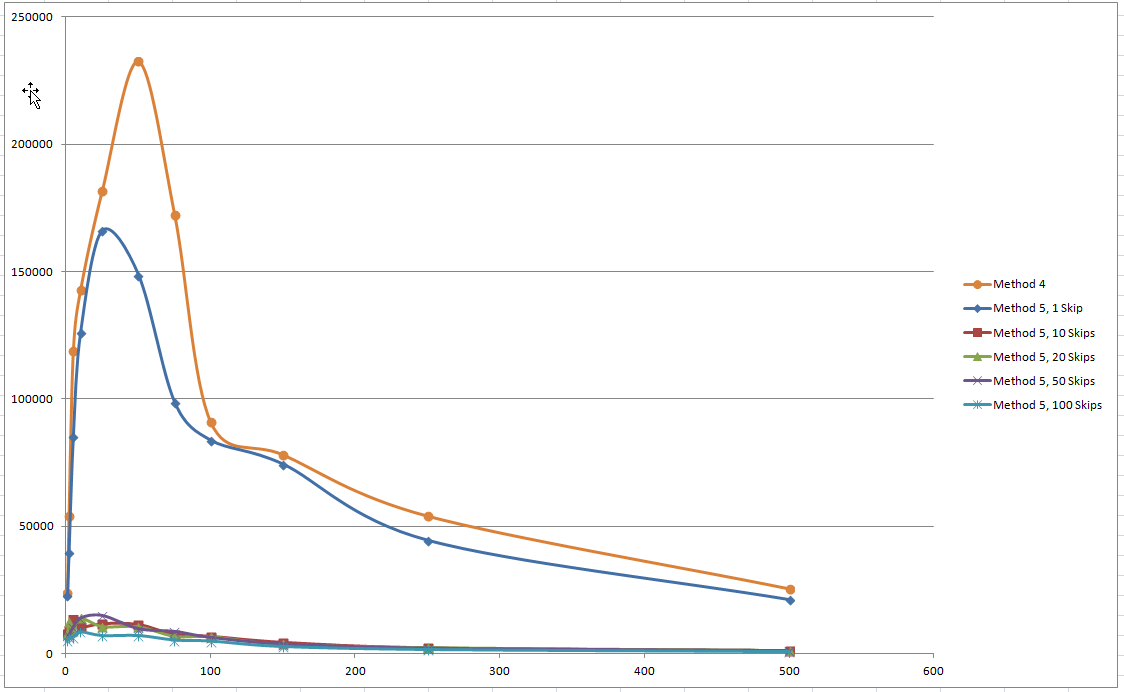
Method 5 was the odd one out so I treated the results separately. I wanted to find out if the performance gain I was with Method 4 was because the cells to be updated were in the same order as the columns in the database. Well it turns out it’s a lot more complex than that. Putting the cells to be updated in order does appear to make a little difference but not a lot. What makes the biggest difference is how many cells you update or more precisely how many you don’t update.
It would seem that SQL Server has two modes of operation when performing an update either delete the row and re-insert it or update in place. It strongly favours update in place but over a certain threshold it will delete and insert. I don’t know where the threshold is exactly but it would seem to be around 95% of the cells changing in a row causes a delete and insert – 1 skipped cell caused a delete and insert 10 skipped rows didn’t. Skipping cells caused the c/s to drop but as long as it was still in the delete and insert area it was very fast.
Conclusion
Armed with this knowledge I’m going to go back to my application and switch it over to caching updates and submitting them in batches. Since updating a whole row appears to be the fastest technique that is what I’ll use. Essentially I’ll wait until I have 50 heavily updated rows and then just dump them all on the database in one batch. As part of my data analysis I calculated a time to totally update the test table using the various different methods. With Method 1 at 1 query a batch it would take about 32 hours with Method 4 at 50 queries a batch it would take 43 seconds a speed up of 2611 times! For reference the insert queries that built the test table took 14 seconds so the update time of 43 seconds is well within the bounds of believable.